Introduction#
Note
This book is still under construction! There are many features, improvements we would like to make in the long term. Namely, some of the diagrams are currently hand-drawn and the hope is to improve these with animations and cleaner, code-generated figures in the future!
We are also always looking for feedback and help on the book. Feel free to join our GitHub community to help us improve the book!
Welcome! 🎉 !!!
If you’re here, you’ve probably at least heard the term “machine learning” or “artificial intelligence” somewhere on the internet, the news, or somewhere in your day-to-day life. For better or for worse, machine learning has been an incredible force in shaping the modern world. You would be hard pressed to use any piece of modern technology (including any website) without the influence of machine learning powering some (most?) of your interactions.
Before outlining what this book is and how it’s different than other books, let’s look at an example to try to get a better understanding of what this “machine learning” thing means.
Machine Learning in the Wild#
We’ll come back and formally define what machine learning is and the techniques to implement it. For now, let’s just use the colloquial definition that machine learning is the tools and techniques that let a computer make predictions about the future given past data. This is a good enough approximation for us to begin to appreciate where this is used in our day-to-day tools.
Consider Netflix, the popular streaming platform for movies and TV shows. Just looking at their home page, where might you imagine all of the different places they might be using machine learning to power their website? Take a minute and try to list off places you think it might show up behind the scenes before expanding the box below.
Where might there be Machine Learning in Netflix?
Here are just a few of the ones we can think of at the top of our head, and almost all of these have to do with recommendation. Netflix uses computers to decide, based on your past viewing history, which shows it should recommend to make you more likely to watch the shows they recommend. Here are just a few places they shape their recommendations to you:
Which show to show in the banner position (in the screenshot above, it is “Never Have I Ever”)
Which shows to list in the categories (e.g., “TV Shows”) below the banner
Which categories to show you in the first place. If you like action movies, it will likely show you an action category.
Even once they decide to recommend a show (e.g., “Stranger Things”), they also use machine learning to decide which cover art they should use that would make you more likely to watch that show.

And there are so many more that we might not even know about! There are likely even algorithms behind the scenes helping Netflix decide which shows to invest in and even create in the future!
Why Learning Machine Learning Matters#
And all of this is just for one site used for watching TV! If there is so much going on behind the scenes there, imagine all of the ways it can be used in life-changing applications used in our society.
Machine Learning has amazing power to make applications from ones that are fun (teaching a computer to make pasta) to ones that can be used for great social good (detecting ear infections with a smartphone app).
But as the maxim of every superhero movie says, “with great power comes great responsibility.” These machine learning tools are also used in incredibly high-stakes applications such as the criminal justice system, where they have been found to produce biased outcomes. And what’s more, they are being used increasingly in more and more domains such as our elections, national defense, health, and transportation.
Without being informed about what these models are doing and how they work, we have no hope of being able to assess and critique where we should and should not be using them. Our hope in this book is that we can show you the awesome potential of these systems and how you build them well. At the same time, we want you to be considering the serious ramifications of automation that these models afford and how to avoid some dangerous pitfalls that can end up harming people.
ML in the Real World#
One of my favorite(?) tweets about the ways machine learning is used in the real world is this one. While it’s a few years old at this point, it highlights that these systems with huge amounts of uncertainty are being deployed in settings with extremely real consequences. Where high amounts of uncertainty in the part of the decision maker are probably undesirable.
It’s terrifying that both of these things are true at the same time in this world:
— Eddy Dever (@EddyDever) May 13, 2018
• computers drive cars around
• the state of the art test to check that you’re not a computer is whether you can successful identify stop signs in pictures

Fig. 1 An ‘adversarial’ stop sign that gets classified as a “45 MPH” sign.#
Underscoring the fact that deployed ML systems have all of this uncertainty in the first place, actors can try to manipulate these systems for their own gain (or others harm). For example, some researchers have shown that by strategically manipulating a picture of a stop sign as in Fig. 1, they could make a real-world ML system make a mistake. for classifying images not only incorrectly, but confidently, predict the image was a sign indicating the speed limit was 45 MPH in that area .
Not only are we concerned by bad actors maliciously manipulating ML systems to cause harm, even the systems themselves can be designed to do harm without the creators even intending it in the first place. For example, the famous Gender Shades project showed that production facial recognition systems disproportionately make errors on faces of darker skinned women then it does lighter skinned men as seen in Fig. 2.
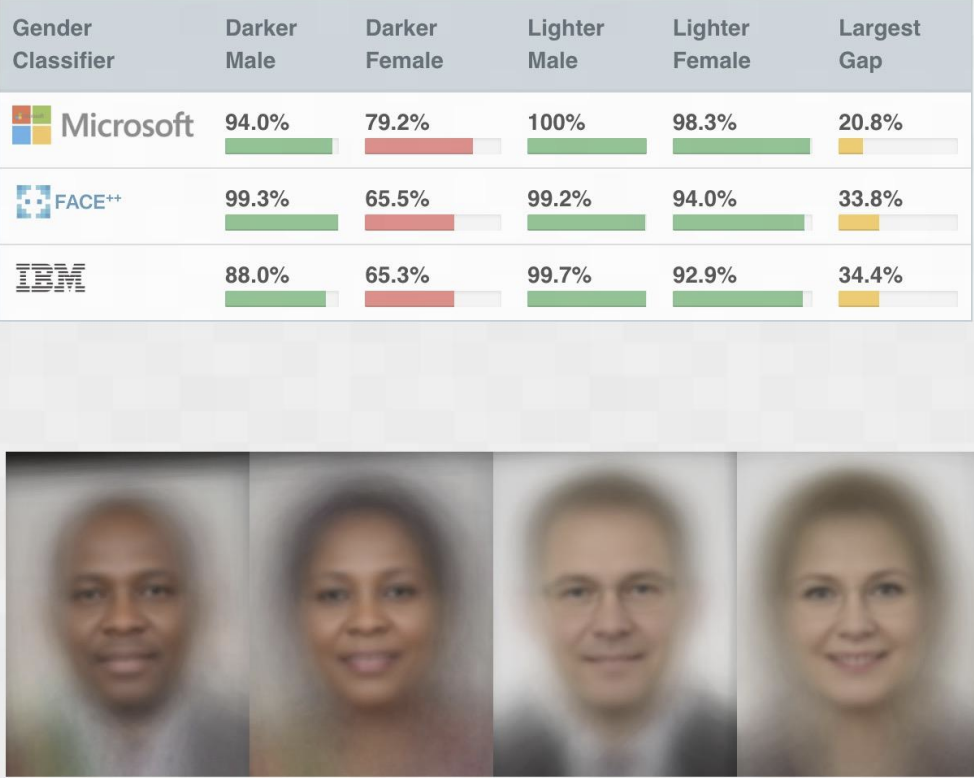
Fig. 2 “Facial Recognition is Accurate, if You’re a White Guy”#
Most would assume that the creators of these facial recognition systems didn’t intentionally code their systems to be worse on people of color, so where did these biased outcomes come from? Almost always with machine learning systems, they are just automated ways of reflecting trends in the data they trained on. A common phrase said by machine learning practitioners is “Garbage in, \(\rightarrow\) Garbage out”. The same is true for data that encodes structural bias in our society. Bias in \(\rightarrow\) Bias out.
You might be wondering how bias can enter the data our models train on. Well the simple answer is most data is drawn from the real world, and the real world encodes historical and present biases against certain populations of people.
Take for example a model that is trained on records of criminal incidences in cities. Many such systems are trained on police records and used to deploy police across the city to help prevent crime; usually with a particular focus to prevent violent crimes. While these systems are often well-intentioned to stop these sorts of violent crimes, they often aren’t the only types of crimes recorded. For example, they often record petty crimes like loitering, marijuana possession, etc. that police pick up on their patrols. The nature of theses crimes (or even if they are crimes at all) are far less severe than the violent crimes they were originally trying to stop. But these non-violent crimes then fill up the databases, and the models’ predictions now reflect their presence and now predict crime is more likely in that area. Now a system designed to to stop violent crimes is primarily predicting where non-violent crimes occur. This now creates a cycle where the model now sends more police to those areas, where they find more non-violent crimes to report, further justifying even more police being sent to those neighborhoods. And these neighborhoods that end up being over-policed generally are poorer neighborhoods that are more likely to inhabit people of color (Fig. 3).

Fig. 3 Predictive Policing software disproportionately targets low-income, Black, and Latino neighborhoods#
But note, none of this is the “fault” of the machine learning model. It isn’t intentionally setting out to over-police communities of color. In fact, it has no intentions as all as it is not a human being you can ascribe malintent towards. A more correct place to put “fault” in the system is the model builder, and what data they decide to include and exclude in their model. Even though they likely included this data without the intent of discrimination (“more data is better, right?”), they are the ones that made the decision to include it in the first place. They also, for example, chose to not include data such as the multitude of financial crimes perpetrated in business centers of cities (Fig. 4), despite this white-collar crime costs citizens over $300 billion annually.
The (biased) outputs of a model are results of intentional and unintentional modeling choices of the ML practitioner. So it is our job, to ensure we are aware of the modeling choices we make as practitioners and take ownership of the potentially unintended consequences of them. Our job will be to understand the theoretical assumptions and limitations of these models, and practice how to apply them and be aware of their limitations to avoid many of the most common pitfalls when deploying models.
The remaining part of this chapter is broken into 3 parts. Before we give a broad overview of what ML is and the things you will see in this book at the end of this chapter, we we want to establish some of the values we are bringing in as authors of this book and how to effectively learn from this book.
What is this Book?#
Our Values#
Our values determine what we prioritize in structure and content. This is not to say these are the only things that should be valued, but these are the ones we use as a guiding principle for this book.
First, it is critical that everyone understands how machine learning is used in our society. We’ve already highlighted why we think everyone learning this is important, but wanted to write it down as a core value.
We intentionally used a pretty vague word there: “understand”. To understand something can mean different things to different people depending on their goals and where they are in their educational journey. We can’t determine the things you will get out of this book (we’ll talk in a bit about how learning works), but the examples and applications we show try to hit a wide range of possibilities to give you ideas of what these systems can do and how they work internally.
Since there are so many concepts in ML and places they can be applied, we can’t feasibly show them all. If we leave out a concept or application, it’s not because it isn’t important! Instead, it’s almost always a matter of trying to use an example that’s easier for a broader audience to understand.
Second, anyone can learn machine learning! While this is true for any topic1, it’s important to highlight in the case of machine learning. ML is notoriously seen as a difficult topic to master due to a traditional focus on advanced mathematical details and proofs. While those ideas are important for an expert in machine learning to know, they aren’t necessary for forming an intuition for the key ideas of ML. So this book is not going to go rigorously into the mathematics behind ML, but instead tries to make the ideas intuitive and show you how to apply them.
This does not mean we won’t use math at all! While we try to minimize pre-requisite knowledge, we still require some2. Mathematical notation can be very effective for communication and we use it frequently to communicate more precisely/effectively.
These two values hopefully give you a good idea of our approach for how we teach machine learning to a broad audience. If this does not sound like the book that meets what you are hoping to learn (e.g., you want a much more rigorous mathematical discussion of ML or proofs behind the techniques), we recommend some other books that are fantastic in those spaces.
The Elements of Statistical Learning, Trevor Hastie, Robert Tibshirani, Jerome Friedman.
Machine Learning: A Probabilistic Perspective, Kevin Murphy
Foundations of Machine Learning, Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar
How Learning Works#
Learning is a complex process that whole fields of research focus on learning how learning works. The research of effective learning was summarized very well in Make it Stick by Peter C. Brown, Henry L. Roediger III, and Mark A. McDaniel3.
The book outlines two very popular, but ineffective, learning strategies:
Re-reading the same text multiple times until you “get it”.
Massed practice, or practicing the same skill/concept over and over until you get it right. This is a tendency many people have when cramming for something like a test.
Both of these strategies are popular because they make you feel like you are making progress. However, there is little evidence that they are actually effective strategies for longer-term retention or transfer of knowledge.
It turns out that learning effectively is hard work and will challenge you throughout the process; often if a strategy feels easy, that might be a good sign it’s not effective. In “Make it Stick”, they argue the most important thing to learning effectively is being an active participant in the process. When you are taking charge of your learning, you will face many setbacks; you shouldn’t perceive those as failures, but instead as areas to grow. “Make it Stick” argues that active learning involves three key steps:
Practice retrieving new learning from memory. As you are reading, constantly pause and reflect on the new things you have read. Quiz yourself on the new content to make sure you understood it the first time around. Spend time generating knowledge by trying to answer questions on your own before looking at the answer. Elaborate on the concepts you are learning as if you were describing them to someone else; this forces you to summarize what you learned and synthesize it with your past knowledge.
Spaced repetition is incredibly important. Learning a concept isn’t a “one-then-done” ordeal. Effectively using what you learned requires retrieving information from memory. One of the best ways to practice this retrieval is to increasingly space out the times in which you test retrieving the information (e.g., 1 day, 1 week, 1 month, etc.).
A great tool for managing this spacing is Anki. Anki is a flashcard app that has a built-in features for spaced-repetition; it gives you a challenge to master a certain number of cards a day and spaces out when you see certain cards based on that mastery.
-
Interleaving your practice. Instead of practicing all the concepts until mastery for Chapter 1 before moving to Chapter 2, you should mix it up and test them together. Retrieving knowledge in real life rarely has a context like “I’m studying for Chapter 1 right now, so I only need to think of Chapter 1 things”. In reality, you will need to practice bringing up any subset of knowledge. Therefore, your practice should reflect that goal if you want to see improvements of retrieval in realistic contexts4.
When learning about ML in our book, we recommend that you employ these three study tips. You should be building up meaningful notes, reflecting what you’ve learned and relating it to past concepts, testing yourself regularly, and spacing-out and mixing-up your practice. We highly recommend (would require it if we could) using a tool like Anki to help you test yourself on concepts. It’s rare that we care about a word-for-word definition of a term or formula, but instead care about the intuition and understanding that comes from being familiar with that concept. Don’t penalize yourself when studying for messing up a single word as long as you can assess that you have understood that concept (don’t worry, it will always come back later in Anki).
Introduction to Machine Learning#
One of the most general, albeit pretty abstract, definitions of machine learning is one of the most cited ones:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
—Tom M. Mitchell

Fig. 5 Pictorial representation of these steps.#
This is just trying to state in a very formal manner that machine learning is a program that improves at some task by learning from data rather than a human hard-coding the rules of the task.
For example, consider the task of building a system that classifies an image as containing a dog or a cat. One approach would be to try to write a program (e.g., a Python program) that looks at the pixels of the picture in a big if/else statement to make the decision. You (nor I) would really have any idea where to start writing such a program.
Instead, the machine learning approach is to feed a bunch of images that have already been labelled as cat images or dog images as input to some learning algorithm5, and letting that algorithm learn the patterns from the data itself. The ultimate goal of such a system is to train the computer to not just be able to answer this dog-vs.-cat question for images it has seen, but also to generalize to any dog or cat picture it might encounter in the future.
We’ll come back to a more detailed explanation of this pipeline in the next chapter.
Overview of Book#
Case Studies#
We will tackle this introduction to machine learning with 5 overarching case studies to guide us. As we mentioned before, the contexts that these case studies focus on are not the only applications that are of import in machine learning. We spend the majority of our focus on these five examples for consistency and simplicity. This helps you form more explicit connections between the concepts. Each case study will span more than one chapter as indicated in the table of contents; each chapter corresponds roughly to one lecture of the UW CSE/STAT 416 course.
The five case studies we will examine in this book are:
Regression: Learning how to predict the price of a house.
Classification: Learning how to identify if a restaurant review is good or bad (sentiment analysis).
Document Retrieval and Clustering: Given a news article, suggest similar ones that the reader might be interested in.
Recommender Systems: Given the past purchases of a user, what products should we recommend?
Deep Learning: Recognizing objects in images.
Topics#
As a brief (and incomplete) list of topics we will cover:
Models: Different machine learning models that can be used.
Linear regression, regularized approaches (ridge, LASSO)
Linear classifiers: logistic regression
Non-linear models: decision trees and ensemble methods
Nearest neighbors, clustering, kernel methods
Recommender systems
Neural networks and deep learning
Algorithms: Different algorithms for learning these models.
Gradient descent and its variations
Boosting and bagging
K-means
Agglomerative and divisive clustering
Hyperparameter optimization
Concepts: High-level ideas from machine learning, computer science, statistics, and mathematics.
Point estimation, Maximum likelihood estimation (MLE)
Loss functions, bias-variance tradeoff, cross-validation
Sparsity, overfitting, model selection
Decision boundaries
With that, we have introduced what this book is about and some intentions for how it is structured. Our hope is that you find this book exciting and helps you build intuition for this incredibly important field!